We continue looking at the Transformer architecture from where we left from Part 1. When we’d stopped, we’d set up the Encoder stack, but had stopped short of adding positional encoding, and starting work on the Decoder stack. In this post, we will focus on setting up the training cycle.
Specifically, we will cover:
- Positional Encoding
- Decoder stack, including the masked multi-head attention mechanism
- Set up the basic training regime via Teacher Forcing
We will also lay out the dimensional analysis a little more clearly, and add necessary unit tests to verify intended functionality. The code is available here.
Positional Encoding
You can see the code for visualising the positional encoding here. Both images below show the encoding map at different levels of zoom.
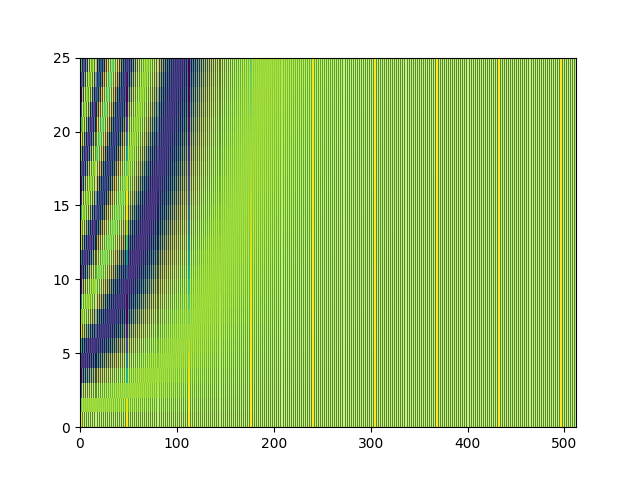
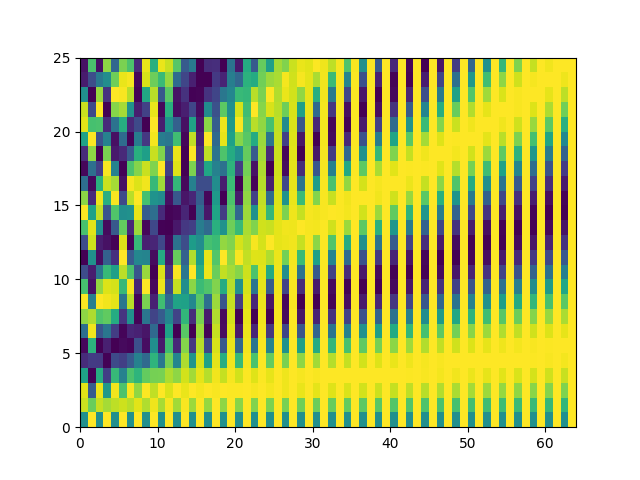
The code in the main Transformer implementation which implements the positional embedding is shown below.
# The encoder output is injected directly into the sublayer of every Decoder. To build up the chain of Decoders
# in PyTorch, so that we can put the full stack inside a Sequential block, we simply inject the encoder output
# to the root Decoder, and have it output the encoder output (together with the actual Decoder output) as part of
# the Decoder's actual output to make it easy for the next Decoder in the stack to consume the Encoder and Decoder
# outputs
def forward(self, input):
encoder_output, previous_stage_output = input
masked_mh_output = self.masked_multiheaded_attention_layer(
self.masked_qkv_source.forward(previous_stage_output))
input_qkv = self.unmasked_qkv_source.forward((encoder_output, masked_mh_output))
mh_output = self.multiheaded_attention_layer(input_qkv)
# Adds the residual connection to the output of the attention layer
layer_normed_multihead_output = self.layer_norm(mh_output + previous_stage_output)
ffnn_outputs = torch.stack(
list(map(lambda attention_vector: self.feedforward_layer(attention_vector), layer_normed_multihead_output)))
layer_normed_ffnn_output = self.layer_norm(ffnn_outputs + layer_normed_multihead_output)
return (encoder_output, layer_normed_ffnn_output)
Data Flow
The diagram below (you’ll need to zoom in) shows the data flow for a single Encoder/Decoder, with 8 attention blocks per multihead attention layer. \(n\) represents the number of words passed into the Encoder. \(m\) represents the number of words passed into the Decoder. \(V\) represents the length of the full vocabulary.
The dimensions of the data at each stage are depicted to facilitate understanding.
graph LR;
subgraph Encoder
encoder_src[Source Text]--nx512-->pos_encoding[Positional Encoding];
pos_encoding--nx512-->qkv_encoder[QKV Layer]
qkv_encoder--Q=nx64-->multihead_attn_1[Attention 1]
qkv_encoder--K=nx64-->multihead_attn_1
qkv_encoder--V=nx64-->multihead_attn_1
qkv_encoder--Q=nx64-->multihead_attn_2[Attention 2]
qkv_encoder--K=nx64-->multihead_attn_2
qkv_encoder--V=nx64-->multihead_attn_2
qkv_encoder--Q=nx64-->multihead_attn_3[Attention 3]
qkv_encoder--K=nx64-->multihead_attn_3
qkv_encoder--V=nx64-->multihead_attn_3
qkv_encoder--Q=nx64-->multihead_attn_4[Attention 4]
qkv_encoder--K=nx64-->multihead_attn_4
qkv_encoder--V=nx64-->multihead_attn_4
qkv_encoder--Q=nx64-->multihead_attn_5[Attention 5]
qkv_encoder--K=nx64-->multihead_attn_5
qkv_encoder--V=nx64-->multihead_attn_5
qkv_encoder--Q=nx64-->multihead_attn_6[Attention 6]
qkv_encoder--K=nx64-->multihead_attn_6
qkv_encoder--V=nx64-->multihead_attn_6
qkv_encoder--Q=nx64-->multihead_attn_7[Attention 7]
qkv_encoder--K=nx64-->multihead_attn_7
qkv_encoder--V=nx64-->multihead_attn_7
qkv_encoder--Q=nx64-->multihead_attn_8[Attention 8]
qkv_encoder--K=nx64-->multihead_attn_8
qkv_encoder--V=nx64-->multihead_attn_8
subgraph EncoderMultiheadAttention[Encoder Multihead Attention]
multihead_attn_1--nx64-->concat((Concatenate))
multihead_attn_2--nx64-->concat
multihead_attn_3--nx64-->concat
multihead_attn_4--nx64-->concat
multihead_attn_5--nx64-->concat
multihead_attn_6--nx64-->concat
multihead_attn_7--nx64-->concat
multihead_attn_8--nx64-->concat
end
concat--nx512-->linear_reproject[Linear Reprojection]
linear_reproject--1x512-->ffnn_encoder_1[FFNN 1]
linear_reproject--1x512-->ffnn_encoder_2[FFNN 2]
linear_reproject--1x512-->ffnn_encoder_t[FFNN x]
linear_reproject--1x512-->ffnn_encoder_n[FFNN n]
subgraph FfnnEncoder[Feed Forward Neural Network]
ffnn_encoder_1--1x512-->stack_encoder((Stack))
ffnn_encoder_2--1x512-->stack_encoder
ffnn_encoder_t--1x512-->stack_encoder
ffnn_encoder_n--1x512-->stack_encoder
end
stack_encoder--nx512-->encoder_output[Encoder Output]
end
subgraph Decoder
decoder_target[Decoder Target]--mx512-->pos_encoding_2[Positional Encoding]
pos_encoding_2--mx512-->qkv_decoder_1[QKV Layer]
qkv_decoder_1--Q=mx64-->multihead_attn_masked_1[Attention 1]
qkv_decoder_1--K=mx64-->multihead_attn_masked_1
qkv_decoder_1--V=mx64-->multihead_attn_masked_1
qkv_decoder_1--Q=mx64-->multihead_attn_masked_2[Attention 2]
qkv_decoder_1--K=mx64-->multihead_attn_masked_2
qkv_decoder_1--V=mx64-->multihead_attn_masked_2
qkv_decoder_1--Q=mx64-->multihead_attn_masked_3[Attention 3]
qkv_decoder_1--K=mx64-->multihead_attn_masked_3
qkv_decoder_1--V=mx64-->multihead_attn_masked_3
qkv_decoder_1--Q=mx64-->multihead_attn_masked_4[Attention 4]
qkv_decoder_1--K=mx64-->multihead_attn_masked_4
qkv_decoder_1--V=mx64-->multihead_attn_masked_4
qkv_decoder_1--Q=mx64-->multihead_attn_masked_5[Attention 5]
qkv_decoder_1--K=mx64-->multihead_attn_masked_5
qkv_decoder_1--V=mx64-->multihead_attn_masked_5
qkv_decoder_1--Q=mx64-->multihead_attn_masked_6[Attention 6]
qkv_decoder_1--K=mx64-->multihead_attn_masked_6
qkv_decoder_1--V=mx64-->multihead_attn_masked_6
qkv_decoder_1--Q=mx64-->multihead_attn_masked_7[Attention 7]
qkv_decoder_1--K=mx64-->multihead_attn_masked_7
qkv_decoder_1--V=mx64-->multihead_attn_masked_7
qkv_decoder_1--Q=mx64-->multihead_attn_masked_8[Attention 8]
qkv_decoder_1--K=mx64-->multihead_attn_masked_8
qkv_decoder_1--V=mx64-->multihead_attn_masked_8
subgraph DecoderMaskedMultiheadAttention[Decoder Masked Multihead Attention]
multihead_attn_masked_1--mx64-->concat_masked((Concatenate))
multihead_attn_masked_2--mx64-->concat_masked
multihead_attn_masked_3--mx64-->concat_masked
multihead_attn_masked_4--mx64-->concat_masked
multihead_attn_masked_5--mx64-->concat_masked
multihead_attn_masked_6--mx64-->concat_masked
multihead_attn_masked_7--mx64-->concat_masked
multihead_attn_masked_8--mx64-->concat_masked
end
concat_masked--mx512-->linear_reproject_masked[Linear Reprojection]
linear_reproject_masked--1x512-->ffnn_encoder_1_masked[FFNN 1]
linear_reproject_masked--1x512-->ffnn_encoder_2_masked[FFNN 2]
linear_reproject_masked--1x512-->ffnn_encoder_t_masked[FFNN x]
linear_reproject_masked--1x512-->ffnn_encoder_n_masked[FFNN n]
subgraph FfnnEncoderMasked[Feed Forward Neural Network]
ffnn_encoder_1_masked--1x512-->stack_decoder_masked((Stack))
ffnn_encoder_2_masked--1x512-->stack_decoder_masked
ffnn_encoder_t_masked--1x512-->stack_decoder_masked
ffnn_encoder_n_masked--1x512-->stack_decoder_masked
end
stack_decoder_masked--mx512-->query_project[Query Projection]
encoder_output--nx512-->kv_project_decoder[Key-Value Projection]
query_project--Q=mx64-->multihead_attn_unmasked_1[Attention 1]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_1
kv_project_decoder--V=nx64-->multihead_attn_unmasked_1
query_project--Q=mx64-->multihead_attn_unmasked_2[Attention 2]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_2
kv_project_decoder--V=nx64-->multihead_attn_unmasked_2
query_project--Q=mx64-->multihead_attn_unmasked_3[Attention 3]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_3
kv_project_decoder--V=nx64-->multihead_attn_unmasked_3
query_project--Q=mx64-->multihead_attn_unmasked_4[Attention 4]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_4
kv_project_decoder--V=nx64-->multihead_attn_unmasked_4
query_project--Q=mx64-->multihead_attn_unmasked_5[Attention 5]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_5
kv_project_decoder--V=nx64-->multihead_attn_unmasked_5
query_project--Q=mx64-->multihead_attn_unmasked_6[Attention 6]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_6
kv_project_decoder--V=nx64-->multihead_attn_unmasked_6
query_project--Q=mx64-->multihead_attn_unmasked_7[Attention 7]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_7
kv_project_decoder--V=nx64-->multihead_attn_unmasked_7
query_project--Q=mx64-->multihead_attn_unmasked_8[Multihead Attention 8]
kv_project_decoder--K=nx64-->multihead_attn_unmasked_8
kv_project_decoder--V=nx64-->multihead_attn_unmasked_8
subgraph DecoderUnmaskedMultiheadAttention[Decoder Unmasked Multihead Attention]
multihead_attn_unmasked_1--mx64-->concat_unmasked((Concatenate))
multihead_attn_unmasked_2--mx64-->concat_unmasked
multihead_attn_unmasked_3--mx64-->concat_unmasked
multihead_attn_unmasked_4--mx64-->concat_unmasked
multihead_attn_unmasked_5--mx64-->concat_unmasked
multihead_attn_unmasked_6--mx64-->concat_unmasked
multihead_attn_unmasked_7--mx64-->concat_unmasked
multihead_attn_unmasked_8--mx64-->concat_unmasked
end
concat_unmasked--mx512-->linear_reproject_unmasked[Linear Reprojection]
linear_reproject_unmasked--1x512-->ffnn_decoder_1_unmasked[FFNN 1]
linear_reproject_unmasked--1x512-->ffnn_decoder_2_unmasked[FFNN 2]
linear_reproject_unmasked--1x512-->ffnn_decoder_t_unmasked[FFNN x]
linear_reproject_unmasked--1x512-->ffnn_decoder_n_unmasked[FFNN n]
subgraph FfnnDecoderUnmasked[Feed Forward Neural Networks]
ffnn_decoder_1_unmasked--1x512-->stack_decoder_unmasked((Stack))
ffnn_decoder_2_unmasked--1x512-->stack_decoder_unmasked
ffnn_decoder_t_unmasked--1x512-->stack_decoder_unmasked
ffnn_decoder_n_unmasked--1x512-->stack_decoder_unmasked
end
end
stack_decoder_unmasked--mx512-->linear[Linear=512xV]
subgraph OutputLayer[Output Layer]
linear--mxV-->softmax[Softmax]
softmax--mxV-->select_max_probabilities[Select Maximum Probability Token for each Position]
select_max_probabilities--1xm-->transformer_output[Transformer Output]
end
Notes on the Code
- The last word in the output is added to the output buffer, during inference.
- The encoder output is injected directly into the sublayer of every Decoder. To build up the chain of Decoders in PyTorch, so that we can put the full stack inside a Sequential block, we simply inject the encoder output to the root Decoder, and have it output the encoder output (together with the actual Decoder output) as part of the Decoder’s actual output to make it easy for the next Decoder in the stack to consume the Encoder and Decoder outputs.
- The code does not set up parameters in a form suitable for optimisation yet. There are several
Module-subclasses which are really only there for the convenience of not having to call theforward()methods explicitly. In a sequel, we will collapse most of the parameters to be part of only a couple ofModulesubclasses.
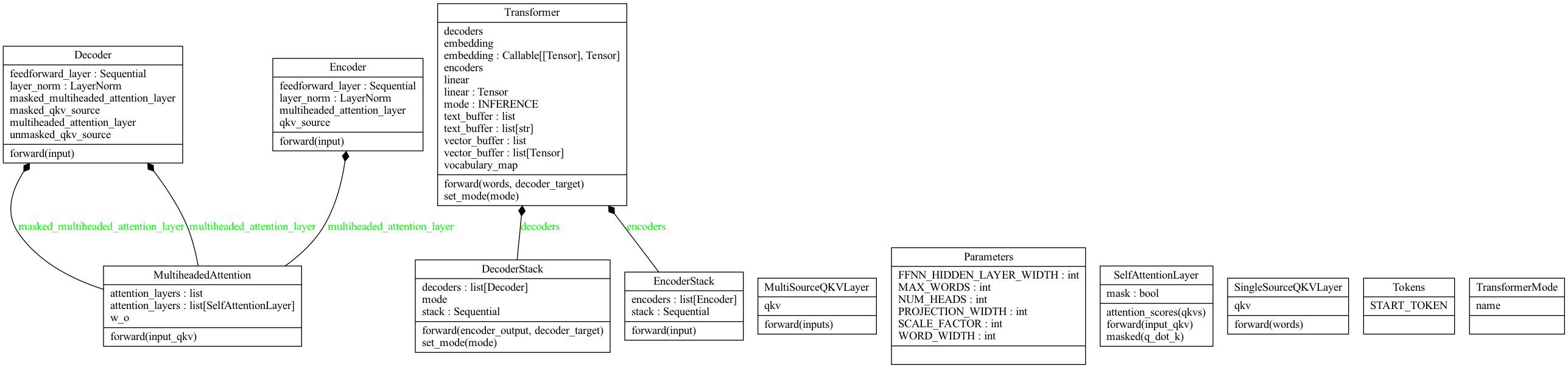
- The class diagram is shown above. The composition hierarchy is quite straightforward, though there are some associations missing because of the shortcomings of the tool used to generate this (Pyreverse).
- Specifically,
DecoderStackcontains a bunch ofDecoders, andEncoderStackcontains a bunch ofEncoders. qkv_sourceandmasked_qkv_sourcecontain instances ofSingleSourceQKVLayer.unmasked_qkv_sourcecontains an instance ofMultiSourceQKVLayer.- Some of the members in the classes are repeated because of Pyreverse duplicating the information from type hints.
- Specifically,
- More notes can be found in the source itself.
Conclusion
We have built and tested the basic Transformer architecture. However, we still need to do the following:
- Build a proper vocabulary. Our current vocabulary is hard-coded, and contains random vectors.
- Several tensors are reused as parameters. Some of these need to be separate parameters.
- There are several
Modulesubclasses. For optimisation, we will need to centralise where we register our parameters. - We still need to train the Transformer.
All of the above, we will work on in the sequel to this post.