This post talks about a technique to build an ANTLR grammar for HLASM (mainframe assembler) from scratch, without writing the grammar of the entire instruction set by hand. The technique creates a parser which reads a table of instruction formats from IBM’s official documentation, and automates the creation of the actual HLASM grammar based on these instruction formats.
The parser is used in Tape/Z.
This post has not been written or edited by AI.
Existing parsers
I needed a grammar for mainframe assembler for working on some of my reverse engineering experiments, while building Tape/Z. The only requirement I had was that the grammar needed to be declarative, since I needed to generate parsers from it, potentially in multiple languages. It could be ANTLR, Treesitter, etc.
I had previously built the parsing component of Cobol-REKT by extracting and reusing parts of the LSP server from the che-che4z-lsp-for-cobol project. The grammar for COBOL/DB2, etc. in that library was written in ANTLR. However, when I surveyed existing support for HLASM, the following were the only ones I could fine:
- z390 emulator: Programmatic Java parser, no explicit grammar
- che-che4z-lsp-for-hlasm: There used to be an ANTLR grammar, but it had many C++-specific extensions, and the most recent version has been completely rewritten in pure C++.
Given that none of the above fit my requirement, I considered what it would take to write my own HLASM grammar.
Practical difficulties of hand-writing a large grammar
Now, HLASM by itself is not complicated. It’s simple opcodes, registers, and offsets. The problem is one of scale. z/OS assembly has well over 2000 instructions, being a CISC instruction set. They are all well-documented, but writing all of them by hand was not practical within the timelines I was looking at.
Thankfully, the formats for these instructions are documented very precisely here. Looking at that, I considered what it might take to automate the creation of this grammar.
The instruction format Meta-Parser
The table in the HLASM spec formally specifies the operand formats. Take for example the operand format for the A opcode.

The idea is: what if we could parse this format and generate the actual desired grammar from the format parse tree? The “meta-parser” (for lack of a better term to describe its role) is less than 40 lines, and looks like so (the full grammar is documented here):
control_register: CONTROL_REGISTER;
access_register: ACCESS_REGISTER;
floating_point_register_pair: FLOATING_POINT_REGISTER_PAIR;
floating_point_register: FLOATING_POINT_REGISTER;
index_register: INDEX_REGISTER;
base_register: BASE_REGISTER;
...
optionalSignedImmediateValue: OPTIONAL_OPEN_PAREN COMMA signed_immediate_value OPTIONAL_CLOSE_PAREN;
optionalRegister: OPTIONAL_OPEN_PAREN COMMA register_operand OPTIONAL_CLOSE_PAREN;
operands: ((operand COMMA)* operand)*;
operand: displacement | floating_point_register_pair | floating_point_register | index_register
| base_register | register_pair | register_operand | control_register | immediate_value | signed_immediate_value
| length_field | mask_field | relative_immediate_operand | vector_register_pair | vector_register
| optionalMaskField | optionalSignedImmediateValue | optionalRegister | access_register;
The HLASM grammar generator
The steps are pretty simple in and of themselves:
- Copy the HTML table into Google Sheets, and export that into a CSV. This gives us the formats ready for ingestion into the format parser.
- Parse the operand formats for each instruction.
- Make a visitor (
HLASMParseRuleBuilderVisitor) visit the operand format’sParseTreeand build object representations of the final grammar elements we wish to emit. - Add extra rules that might not have listed in the base instruction table.
- Emit the string representation of the resulting rule objects into a
.g4file. - …err, profit? :-)
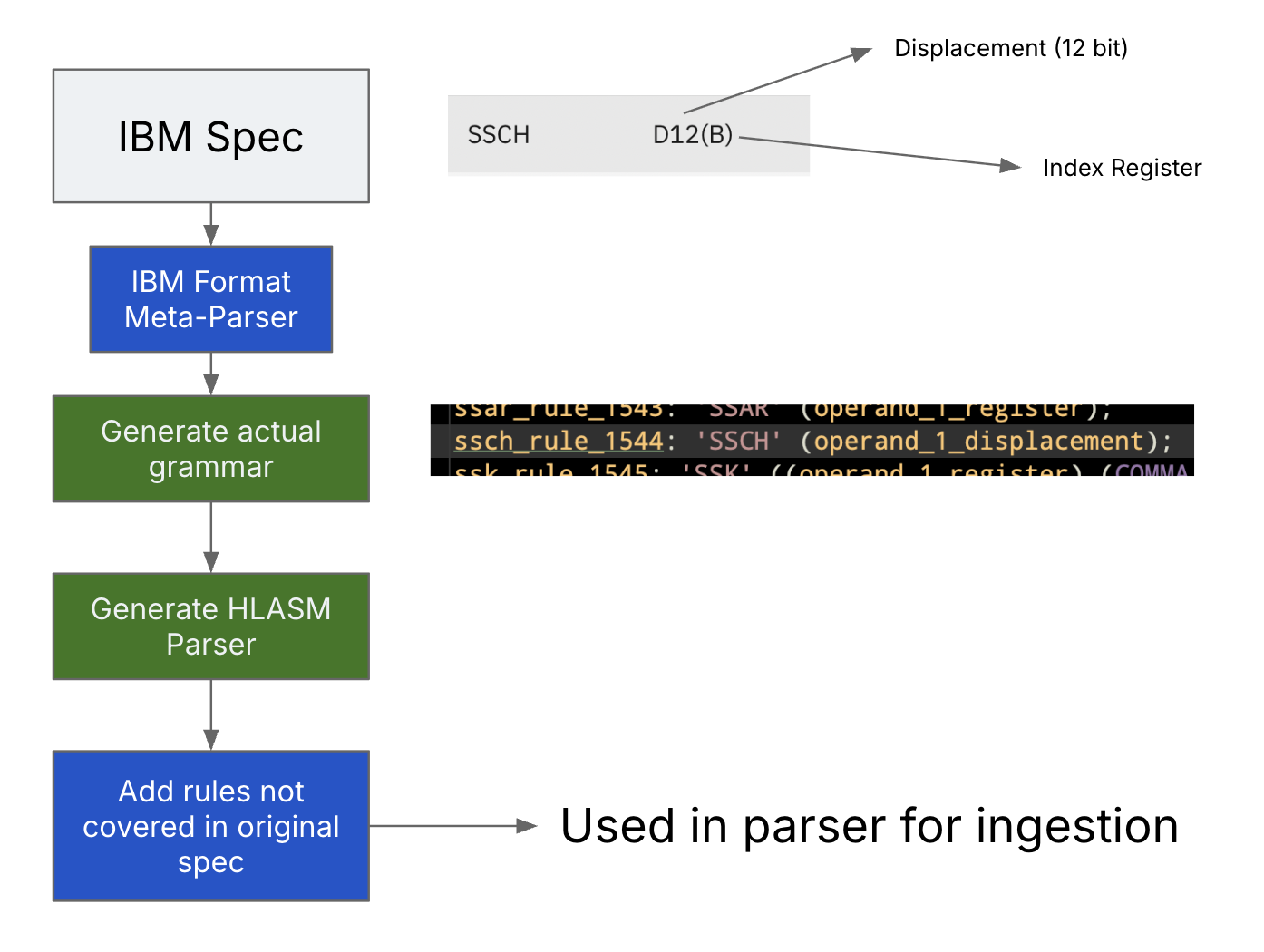
There was one more wrinkle. The generated parser had so many if conditions and switch...case in the top-level scope, that it exceeded some internal JDK limit, and the compiler refused to compile it. Thus, I had to break the 2000+ rules into groups of 400 (a rather arbitrary number), and use that as the first level of matching in the final grammar. Hey, you learn something new everyday!
Here’s an extract from the resulting grammar:
...
a_rule_1: 'A' ((operand_1_register) (COMMA operand_2_displacement));
acontrol_rule_2: 'ACONTROL';
actr_rule_3: 'ACTR';
ad_rule_4: 'AD' ((operand_1_floatingPointRegister) (COMMA operand_2_displacement));
adata_rule_5: 'ADATA';
adb_rule_6: 'ADB' ((operand_1_floatingPointRegister) (COMMA operand_2_displacement));
adbr_rule_7: 'ADBR' ((operand_1_floatingPointRegister) (COMMA operand_2_floatingPointRegister));
adr_rule_8: 'ADR' ((operand_1_floatingPointRegister) (COMMA operand_2_floatingPointRegister));
...
and an example parse tree:
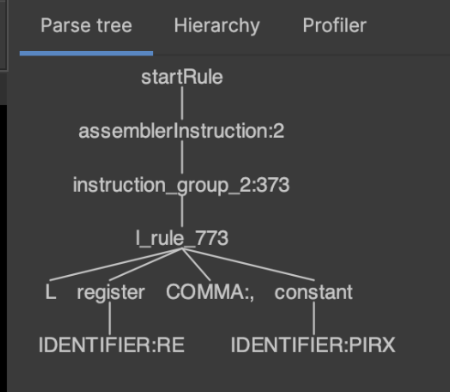
The full grammar is here.
Current Limitations
The instruction formats in the reference are for the base instructions. In practice, most HLASM programs have some higher-abstraction level addressing formats which allow them to use symbols, expressions, etc. which are then lowered by the assembler/macro processor to the form which will ultimately be translated into machine code.
Thus, I had to add some extra operand forms to accomodate this. However, this list is not exhaustive. For example, this parser will not parse operands with the length operator (L'<symbol-or-literal>).